vim2 data¶
In [1]:
%matplotlib inline
import numpy as np
import fem
import os, pickle
import matplotlib.pyplot as plt
data_dir = '../../../data/vim2/'
In [2]:
sv = np.load(os.path.join(data_dir, 'sv.npy'))
with open(os.path.join(data_dir, 'sv_objects2.pkl'), 'rb') as f:
sv_objects = pickle.load(f)
In [3]:
rva = np.load(os.path.join(data_dir, 'subject_1', 'rva.npy'))
trial = 0
rv = rva[:, trial, :]
complete_voxels = np.isclose(np.isnan(rv).sum(1), 0)
rv = rv[complete_voxels]
In [4]:
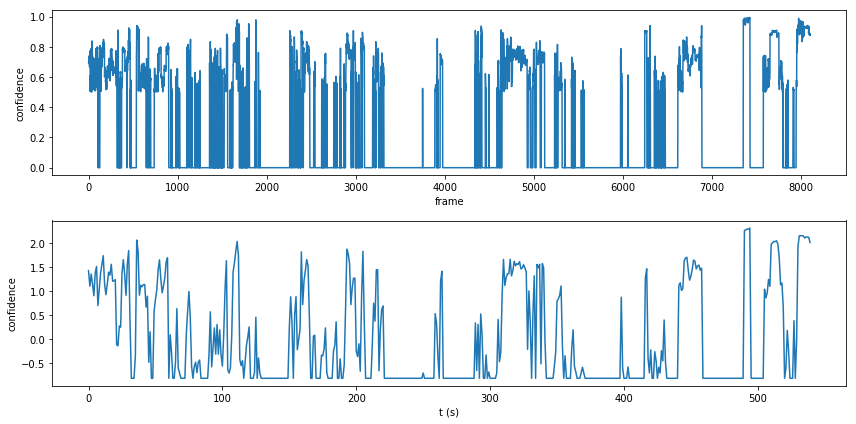
person_confidence = np.array([d['person'] if 'person' in d.keys() else 0 for d in sv_objects])
person_confidence_downsampled = np.array([x.mean() for x in np.split(person_confidence, len(person_confidence)/15)
])
person_confidence_downsampled -= person_confidence_downsampled.mean()
person_confidence_downsampled /= person_confidence_downsampled.std()
fig, ax = plt.subplots(2,1, figsize=(12, 6))
ax[0].plot(person_confidence)
ax[1].plot(person_confidence_downsampled)
for a in ax:
a.set_ylabel('confidence')
ax[0].set_xlabel('frame')
ax[1].set_xlabel('t (s)')
plt.tight_layout()
plt.show()
In [5]:
thin, lag = 11, 5
rv = rv[::thin]
rv = np.roll(rv, lag, axis=1)
x = np.vstack((person_confidence_downsampled[np.newaxis, :], rv))
x = x[:,:-lag]
train_frac = 0.8
split = int(train_frac * x.shape[1])
x_train, x_test = x[:,:split], x[:,split:]
In [6]:
w, d = fem.continuous.fit.fit(x_train[:,:-1], x_train[:,1:], iters=10)
In [7]:
fig, ax = plt.subplots(1, 2, figsize=(8, 4))
ax[0].imshow(w, cmap='seismic')
ax[0].axis('off')
for di in d:
ax[1].plot(di, 'k-')
plt.show()
In [8]:
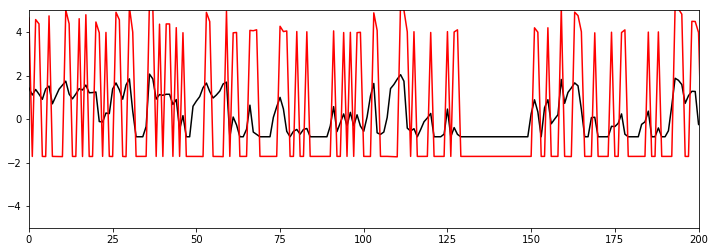
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
ax.plot(person_confidence_downsampled, 'k-')
y = -w[0].dot(x[:,:-1])
ax.plot(y, 'r-')
ax.set_xlim(0, 200)
ax.set_ylim(-5, 5)
plt.show()
In [9]:
fig, ax = plt.subplots(1, 1, figsize=(12, 2))
z1 = x[0,1:] > 0
z2 = y > 0
z3 = z1 == z2
ax.imshow(np.vstack([z1, z2, z3]), cmap='Greys', aspect='auto')
ax.set_yticks(range(3))
ax.set_yticklabels(['true', 'prediction', 'agreement'])
split = int(train_frac * x.shape[1])
print 'train: %f, test: %f' % (z3[:split].mean(), z3[split:].mean())
# lag, accuracy, (thin=11)
# 1, train: 0.563805, test: 0.485981
# 2, train: 0.567442, test: 0.523364
# 3, train: 0.568765, test: 0.485981
# 4, train: 0.567757, test: 0.570093
# 5, train: 0.567757, test: 0.452830
train: 0.567757, test: 0.452830
